
Deep Dive Into Apache Kafka | Storage Internals
In my previous post, we discussed about how different Kafka components work together through a hands on. But if you are looking for in depth understanding of Kafka, knowledge about its storage is very important. So, what do I mean by storage? Well, when I was doing a hands on in my previous post, I was curious to find out how Kafka stores & retrieves messages of a topic. So in this blog post, I tried to the explain the storage internals of Apache Kafka in a simple and practical way.
At the end of this blog post, you will have a good understanding of storage architecture of Apache Kafka. In addition to this, there are a few pointers around how to tune Kafka storage based on your requirements. Without further ado, lets get started.
Note : Before you start reading this post, I would strongly recommend you read & try the hands on in my previous post.
Storage Configuration
If you had a chance to try the hands on in my previous post, you will notice that the brokers were started using configuration files namely broker-0.properties & broker-1.properties. These configuration files contain important parameters that control different components of our Kafka cluster. You can find the complete list of the broker parameters in the Kafka’s official documentation. For now, let us try to look at the most important parameters defined in these configuration files.
| Parameter | Description | broker-0 | broker-1 |
|---|---|---|---|
| broker.id | A unique identifier for each broker | 0 | 1 |
| port | Broker runs on this port | 9092 | 9093 |
| zookeeper.connect | IP and port of running zookeeper instance | localhost:2181 | localhost:2181 |
| log.dirs | Directory where the messages of a topic are stored | /tmp/logs/kafka-logs/broker-0 |
/tmp/logs/kafka-logs/broker-1 |
Among these parameters, our focus in this post will be mainly on the log.dirs parameter. The log.dirs parameter indicates the location of the folder/directory within a broker where the topic messages are stored. This directory has a well defined structure which captures the storage architecture of Kafka.
Generating Data
Before we look at the log directory, we should setup a working Kafka cluster & generate data. The code used in this blog post is available in this repository. Make sure that you clone this repository in your working environment before you proceed further. To make the cluster setup easy, I wrote a bash script setup.sh with all the required commands. Navigate to the hands-on directory & execute the setup as shown below.
cd hands-on/
sh setup.sh
This should do the cluster setup. To generate data, I have written another bash script produce.sh which writes data from the cars.txt to cars topic. Now execute the command given below.
sh produce.sh
This might take a few seconds to complete. After successful execution of the above command, there should be enough data stored in the Kafka cluster for us to proceed further. Let’s now go through the directory structure of broker-0 and practically see how Kafka manages data internally.
The Log directory
From the configuration of broker-0 we know that the data of cars-0(0th partition of topic cars) is stored at/tmp/logs/kafka-logs/broker-0/cars-0. So lets simply execute the ls command to see whats in there.
docker exec -it broker-0 /bin/bash -c 'ls /tmp/logs/kafka-logs/broker-0/cars-0'
This commands results in the following output
00000000000000000000.log
00000000000000000000.index
00000000000000000000.timeindex
00000000000000000035.log
00000000000000000035.index
00000000000000000035.timeindex
We can see a list of files grouped by name with each group having a .log, .index & .timeindex files. These file groups capture the storage internals of a topic’s partition. Let us now dig into the details of this directory structure.
Log Segment
According to the Kafka architecture, topics are divided into partitions which are stored in brokers. This might lead us to think that partition is the standard unit of a topic storage in Kafka. But however, this doesn’t seem to be true. Partitions are further divided into smaller elements called segments which store the topic data.
Each of one of the above groups of files in the log directory represents a segment. The suffix(0 & 35) in the segment’s file name, indicates the base offset (offset of the first messsage) of the segment. For example,
00000000000000000000.* - Capture storage of messages with 0 <= offset < 35.
00000000000000000035.* - Capture storage of messages with offset >= 35.
But, you might wonder, when and how does Kafka know that it has to create a new segment. For this, Kafka relies on a broker property named log.segment.bytes which indicates the maximum size(in bytes) of a segment in the cluster. This size can also be configured at the topic level using segment.bytes property.
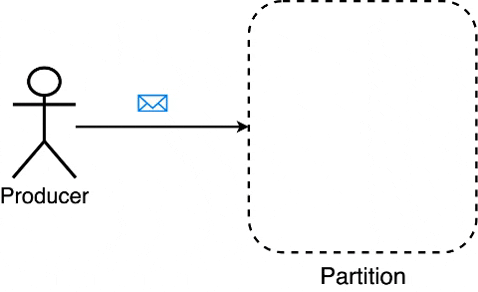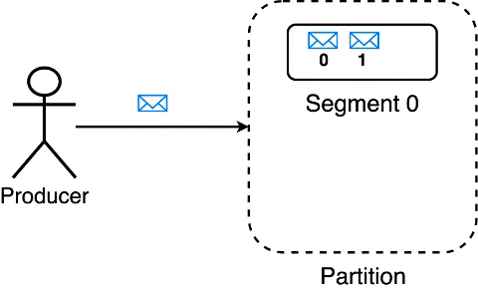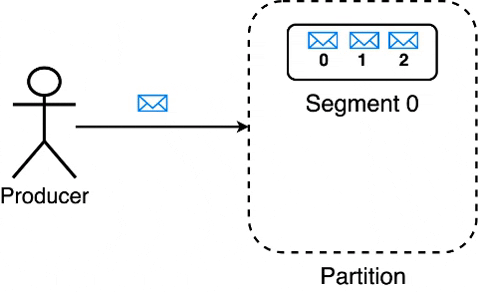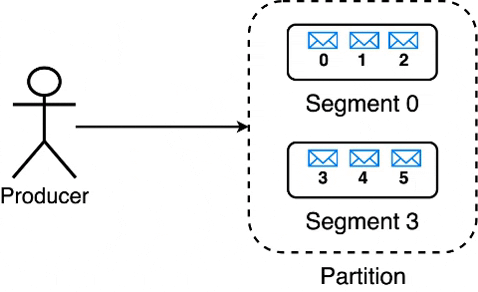
Whenever messages are written to a partition, Kafka writes these messages to a segment until its size(in bytes) reaches the limit specified by log.segment.bytes / segment.bytes. Once this limit is reached, Kafka creates a new segment within the partition & starts writing messages to the new segment.
Within each segment, there are three files with the following extensions - .log, .index & .timeindex. If you try to open and read these files, you will find that the content in these files is not readable. To get a practical understanding, lets go through each one of these files separately and explore their contents.
‘.log’ file
As the name suggests, every message written to a segment is logged in its .log file. Let’s try to read the contents of a .log file, using the command below
docker exec -it broker-0 kafka-run-class.sh kafka.tools.DumpLogSegments --deep-iteration --print-data-log --files /tmp/logs/kafka-logs/broker-0/cars-0/00000000000000000000.log
This commands results in an output shown below
Dumping /tmp/logs/kafka-logs/broker-0/cars-0/00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 6 count: 7 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1586329540137 size: 173 magic: 2 compresscodec: NONE crc: 386807681 isvalid: true
| offset: 0 CreateTime: 1586329540133 keysize: 1 valuesize: 3 sequence: -1 headerKeys: [] key: 2 payload: BMW
| offset: 1 CreateTime: 1586329540135 keysize: 1 valuesize: 9 sequence: -1 headerKeys: [] key: 5 payload: Chevrolet
| offset: 2 CreateTime: 1586329540135 keysize: 1 valuesize: 7 sequence: -1 headerKeys: [] key: 6 payload: Porsche
| offset: 3 CreateTime: 1586329540136 keysize: 2 valuesize: 6 sequence: -1 headerKeys: [] key: 10 payload: Jaguar
| offset: 4 CreateTime: 1586329540136 keysize: 2 valuesize: 5 sequence: -1 headerKeys: [] key: 11 payload: Volvo
| offset: 5 CreateTime: 1586329540136 keysize: 2 valuesize: 10 sequence: -1 headerKeys: [] key: 12 payload: Land Rover
| offset: 6 CreateTime: 1586329540137 keysize: 2 valuesize: 12 sequence: -1 headerKeys: [] key: 15 payload: Aston Martin
.
.
.
baseOffset: 28 lastOffset: 34 count: 7 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 692 CreateTime: 1586329575827 size: 173 magic: 2 compresscodec: NONE crc: 3347769538 isvalid: true
| offset: 28 CreateTime: 1586329575821 keysize: 1 valuesize: 3 sequence: -1 headerKeys: [] key: 2 payload: BMW
| offset: 29 CreateTime: 1586329575823 keysize: 1 valuesize: 9 sequence: -1 headerKeys: [] key: 5 payload: Chevrolet
| offset: 30 CreateTime: 1586329575823 keysize: 1 valuesize: 7 sequence: -1 headerKeys: [] key: 6 payload: Porsche
| offset: 31 CreateTime: 1586329575824 keysize: 2 valuesize: 6 sequence: -1 headerKeys: [] key: 10 payload: Jaguar
| offset: 32 CreateTime: 1586329575825 keysize: 2 valuesize: 5 sequence: -1 headerKeys: [] key: 11 payload: Volvo
| offset: 33 CreateTime: 1586329575825 keysize: 2 valuesize: 10 sequence: -1 headerKeys: [] key: 12 payload: Land Rover
| offset: 34 CreateTime: 1586329575827 keysize: 2 valuesize: 12 sequence: -1 headerKeys: [] key: 15 payload: Aston Martin
Before we understand the result, I should mention that producer batches the messages before it writes to the partition to improve throughput. This is evident from the above result, where we can see messages grouped together in the .log file. For the ease of understanding, the first batch of messages in the above .log file can be represented as follows
| baseOffset | lastOffset | count | position | CreatedTime | size | Messages | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 7 | 0 | 1586329540137 | 173 |
|
- baseOffset : Offset of first message in the batch
- lastOffset : Offset of last message in the batch
- count : Number of messages in the batch
- position : Position of the batch in the file
- CreatedTime :Created time of last message in the batch
- size : Size of the batch(in bytes)
- Messages : List of messages(& its details) in the batch
Thus all the messages along with their details are stored in the .log file.
‘.index’ file
Before we start discussing about the .index file, lets take a small detour to understand the need for .index file. As we know, every consumer has an associated numeric offset for each of its partition(s). This offset indicates the offset of the last processed message of a partition. Since the consumers process messages continuously, extracting a message given an offset should be a very frequent operation.
Lets say the consumer needs to find a message with offset k in a partiton. This should involve two steps
Step 1: Find the appropriate segment for offset k.
Step 2: Extract the message with offset k from this segment.
From our previous discussion on segments, we know that the file name’s suffix indicates the base offset(= offset of the first message) in that segment. Given this information, by doing a simple binary search on the files names within the partition, we can quickly figure out the segment which contains the message for the given offset k. So, Step 1 is sorted.
Now that we have the segment which contains the message, how do we extract that message with offset k?
From the previous section, we know that every message along with its offset is being stored in the .log file. One possible(& naive) way to implement this would be to iterate over the contents of the .log file and extract out the message with offset k. But this is not efficient as the size of the .log file may grow over time, and processing the entire file would be difficult. So how do you think Kafka handles this?
This is where the index file (.index) comes into picture. The index file stores a mapping of relative offset(4 bytes) to a numeric value(4 bytes). This numeric value indicates the position in the .log file where the message with offset = (base offset + relative offset) is located. Let us check out the contents of the .index file by using the command below.
docker exec -it broker-0 kafka-run-class.sh kafka.tools.DumpLogSegments --deep-iteration --print-data-log --files /tmp/logs/kafka-logs/broker-0/cars-0/00000000000000000000.index
This commands results in an output shown below
Dumping /tmp/logs/kafka-logs/broker-0/cars-0/00000000000000000000.index
offset: 20 position: 346
offset: 34 position: 692
The result indicates that the message with offset 20 ( = 0 + 20) is located at position 346 in 00000000000000000000.log file. Similarily the message with offset 34 ( = 0 + 34) is located at position 692.

Given such a mapping, we can easily extract a message within a segment for offset k. Therefore, Step 2 is also sorted. Thus, the .index file & .log file together, provide an efficient way to extract messages given an offset.
But wait, does Kafka store this mapping for every single offset? No. From the above result we can see the mapping only for offsets 20 and 34. Having that said, how does Kafka know when to add a entry in the index file? Kafka uses a broker property named log.index.interval.bytes. This property indicates how frequently (after how many bytes) an index entry would be added. This can also be configured at the topic level using the property index.interval.bytes. By tuning this property, we can control the number of entries in the .index file. Try to play around with this property and see for yourself how the entries in the .index file change.
‘.timeindex’ file
From the previous section we know that .index file contains a mapping of message offsets and their positions. In a similar fashion, the .timeindex file contains the mapping between the message timestamp and its offset (T, offset). The timestamp here refers to the created time of the message. A time index entry (T, offset) indicates that in a given segment, all the messages whose created time > T have their offset > offset. This mapping primarily used to search offsets by timestamp. You can find more details about .timeindex file here.
Let us try to checkout the contents of the .timeindex file in our working example by using the following command.
docker exec -it broker-0 kafka-run-class.sh kafka.tools.DumpLogSegments --deep-iteration --print-data-log --files /tmp/logs/kafka-logs/broker-0/cars-0/00000000000000000000.timeindex
This commands results in an output shown below
Dumping /tmp/logs/kafka-logs/broker-0/cars-0/00000000000000000000.timeindex
timestamp: 1586329557553 offset: 20
timestamp: 1586329575827 offset: 34
We can clearly see the mapping between timestamp(Unix time) and the offsets.
The above mentioned result can be translated as follows
- Messages with 1586329557553 <= created time < 1586329575827, have 20 ( = 0 + 20) <= offset < 34 ( = 0 + 34).
- Messages with created time >= 1586329575827, have their offset >= 34 ( = 0 + 34).
You will notice that these offsets are exactly the same offsets seen in the .index file(discussed in the previous section). This is because, Kafka uses the same property(log.index.interval.bytes / index.interval.bytes) used for .index file, to decide when to add an entry in .timeindex file.
Conclusion
Let’s quickly summarize our learnings from this post
log.dirsindicates the directory where Kafka stores topic data.- Partitions are divided into segments.
log.segment.bytes/segment.bytesindicates the maximum size(in bytes) of a segment..logfile contains details of all the messages..indexfile contains the mapping of message offset to its position in.logfile.- Kafka uses
.index&.logfile to quickly extract the message for a given offset. .timeindexfile contains the mapping of timestamp to message offset..timeindexis used to search messages by timestamp.log.index.interval.bytes/index.interval.bytesindicates the memory size(in bytes) after which an entry in.index/.timeindexfile is added.
After reading this post, we realise that Kafka’s storage is very well structured and distributed. This structure makes it easy to store & retrieve data efficiently. Additionally, you should now have an idea about how to tune Kafka’s storage properties based on your requirements. Hope this post gave you a practical understanding of how Kafka stores and manages data internally. Please do share your feedback in the comments section below. Stay Tuned & Happy coding !!