
Learn Apache Kafka Architecture | The Easy Way
Apache Kafka is a distributed streaming platform. Well known for its scalability & fault tolerance, Apache Kafka is extensively used to build real time data pipelines and streaming applications. It was originally developed by LinkedIn and was later open sourced through Apache Foundation. Apache Kafka is widely used in production by well known companies like Uber, Netflix, Twitter, Spotify, LinkedIn etc. You can find the complete list here. In a recent article published by LinkedIn, more than 7 trillion messages are processed per day which serves as a testament to Kafka’s scale.

Before we discuss the architecture of Kafka it is necessary to understand streaming data and its importance. Streaming data is the data generated continuously from multiple data sources. Processing streaming data is important in applications that require quick actions to be taken in real time based on the data at any given point of time. For instance, in banking applications, credit card fraud needs to be detected and handled in real time which otherwise may lead to a huge losses. For such applications there is a need for a platform that can collect, store & provide an ability to process large volumes of streaming data in a quick and efficient manner.
In any streaming platform, there are two major entities namely producer & consumer. Producer produces data that can be processed by a consumer. In order to handle this workflow efficiently, a streaming platform should possess the following capabilities
- Collect & store data from multiple producers
- Enable data access to multiple consumers
- Able to quickly process large data
- Exhibit Fault Tolerant Behaviour
This is my first post in the series of blogs on Apache Kafka. In this blog post, we are going to discuss the architecture of Apache Kafka and how it meets the above mentioned requirements of a streaming platform.
Note : Throughout this post, streaming data is referred to as message(s).
Architecture
Primarily, Apache Kafka implements a publish subscribe messaging model, popularly known as the pub-sub model. In this model, messages are divided into topics. A topic represents an collection of similar type of messages. A producer can write(publish) messages to multiple topics. Similarily, a consumer can read(subscribe) messages from multiple topics.
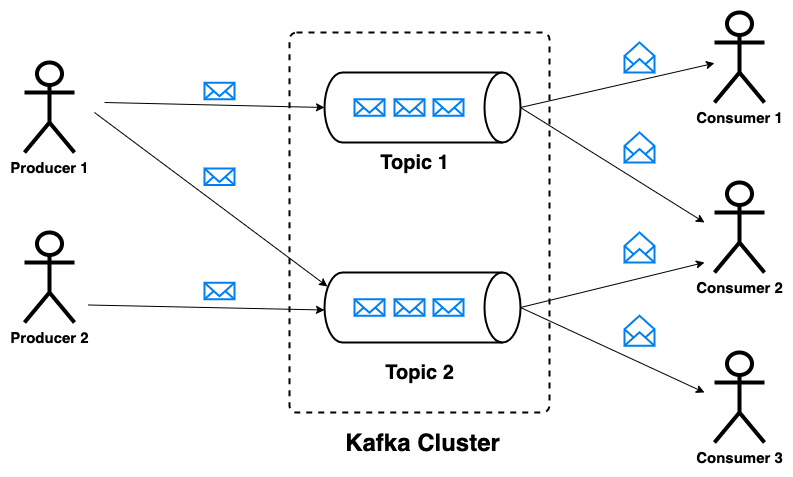
This model gives a lot of flexibility in terms of writing and processing messages. Without further ado, lets go through the components that make the kafka architecture.
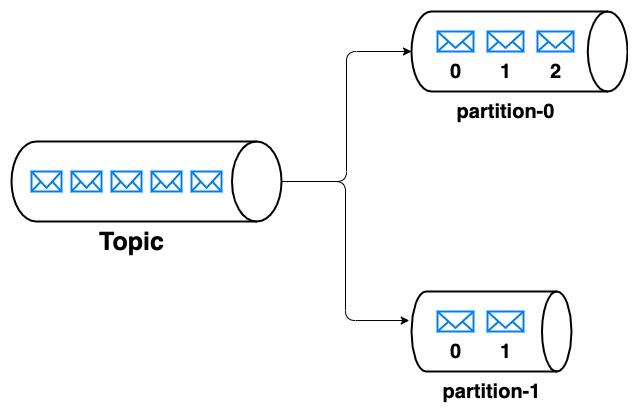
Partition
In kafka, a partition is an ordered immutable collection of messages. Each topic is divided into multiple partitions. Each message in a partition is assigned a unique sequential id named offset.
Producer
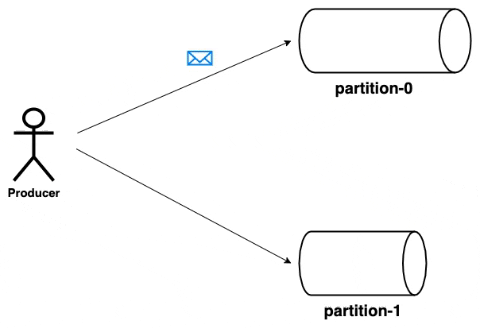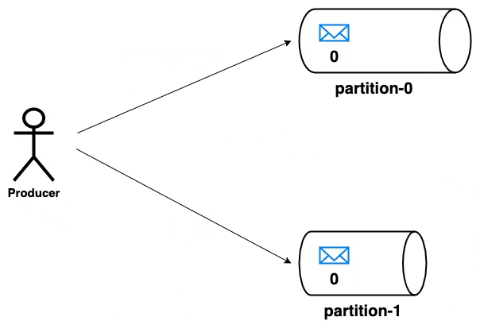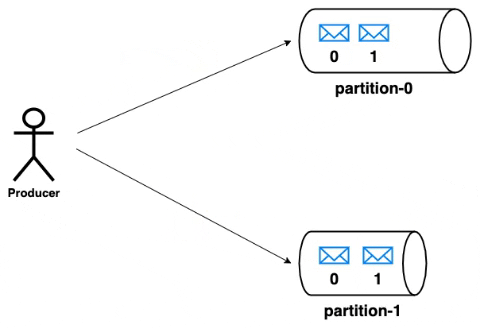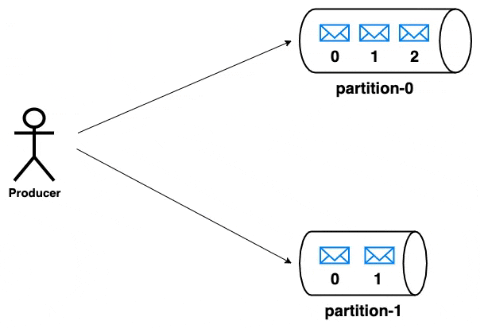
As mentioned previously, producers can write messages to multiple topics. A producer can chose the partition to which the message is to be written. The strategy for the partition selection can be decided by the producer based on the properties of the message. But however, kafka provides a default partitioning strategy when no strategy is provided by the producer. The messages written to a partition will be appended in the order with incremental offsets.
Replication
Kafka supports replication of partitions across brokers. The number of partitions (p) per topic & the number of replicas (n) per partition can be configured. So, the total number of replicas per topic would be p x n. For every partition, one broker acts as a leader, and the other brokers act as its followers. Whenever the message is written to a partition, the leader persists this message to the partition’s replica(s) contained within the leader. The leader also makes sure that each one of the other brokers copy this message to the partition’s replica contained within them. In this way, kafka ensures that every message written to a partition is copied to all the replicas of that partition. Whenever a leader of a partition is disconnected, one of its followers is elected as a leader.
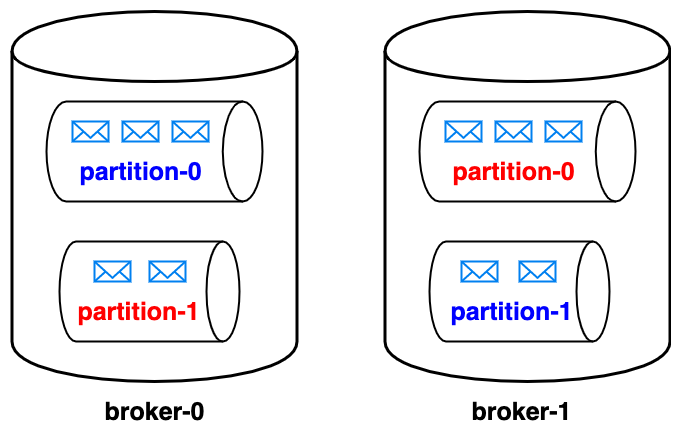
Partitions and replication enable the data of a single topic to be distributed across brokers thus achieving distributed storage & fault tolerance. For instance, let us say our kafka cluster has two brokers broker-0 & broker-1. Our topic has two partitions partition-0 & partition-1 with two replicas each. partition-0, partition-0 represent the replicas of partition-0 for which broker-0 acts as a leader. Similarily, partition-1, partition-1 represent the replicas of partition-1 for which broker-1 acts as a leader. Let us say one of our brokers broker-0(leader of partition-0) goes down due to power outage. We can still have our cluster up and running as we have a replica of partition-0 i.e partition-0 in broker-1. Now, broker-1 is promoted as the leader for the partition-0 thereby achieving fault tolerance.
Consumer
In Kafka, consumers are grouped into consumer groups. A consumer group when subscribed to a topic, ensures that it reads all the messages of that topic. This is achieved by evenly distributing the partitions of the topic across all the consumers within the consumer group. The messages within a given partition are processed by one and only one consumer. In general, consumer reads from the partition’s replica that lives in the leader of that partition. For each partition, the consumer maintains an offset that indicates the offset of last processed message in the partition. This offset helps in ensuring that a message is not processed multiple times. Thus, messages within a topic are consumed parallely by multiple consumers leading to high throughput.
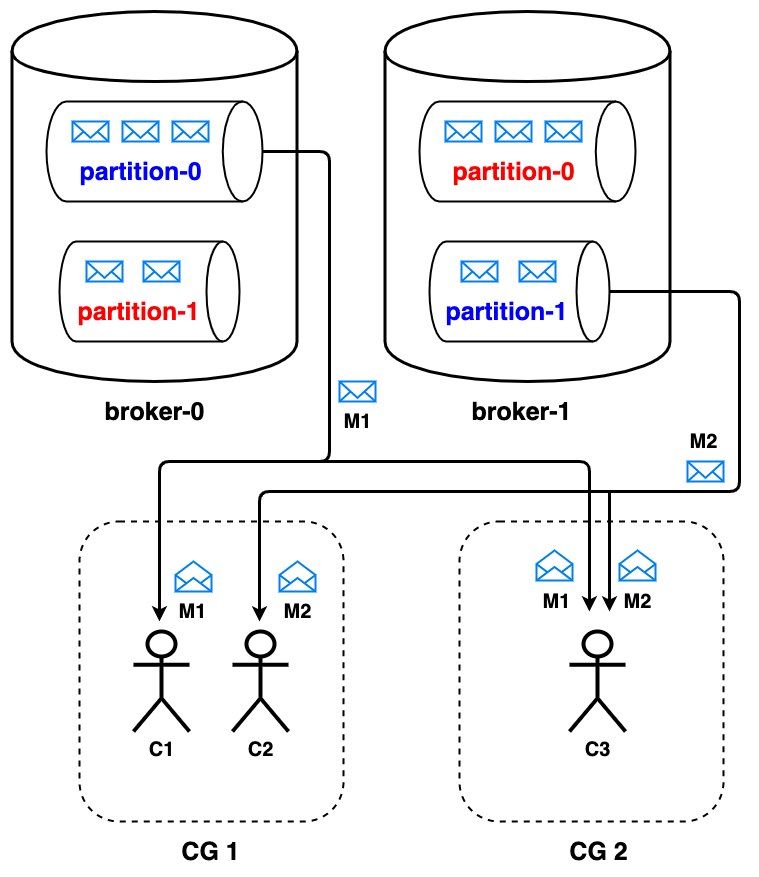
Let’s say we have two consumer groups CG1 and CG2 with two & one consumers respectively. They are subscribed to a topic with two partitions. In case of CG1, the partitions are evenly distributed across consumers C1 and C2, each getting one partition to read from. On the other hand, since CG2 has only one consumer C3, it has to process messages from both the partitions.
Let’s say one of the consumer C1 of a consumer group CG1 goes down. In this case, the consumer group redistributes the partitions among the remaining consumers i.e C2. Therefore, the functional consumer C2 starts reading from both the partitions of the topic. Thus Kafka ensures that each consumer group as a whole, processes all the messages of the subscribed topic. This in a way, also depicts the fault tolerant behaviour of kafka.
Conclusion
Now that we have discussed the architecture of Apache Kafka, let us try to summarize it by justifying how Apache Kafka possesses the capabilities of a streaming platform.
-
Collect & store data from multiple producers : Producers can write data to multiple topics. Topic data is stored across Kafka brokers in a distributed fashion.
-
Enable data access to multiple consumers : Consumers can read data from multiple topics by subscribing to them.
-
Able to quickly process large data : Partitions and consumer groups enable data within a topic to be processed in parallel by multiple consumers leading to high throughput.
-
Exhibit Fault Tolerant Behaviour : With replication of partition across brokers, the cluster can run smoothly even if one or more brokers are down. Additionally, in case of a consumer crash, the consumer group ensures that all the messages of a topic are processed by redistributing the partitions among the remaining consumers.
Hopefully this post has given you some insight into the architecture of Apache Kafka. Please do share your feedback in the comments section below. The next blog post in this series deals with how each one of these components works under the hood. Stay Tuned & Happy coding !!